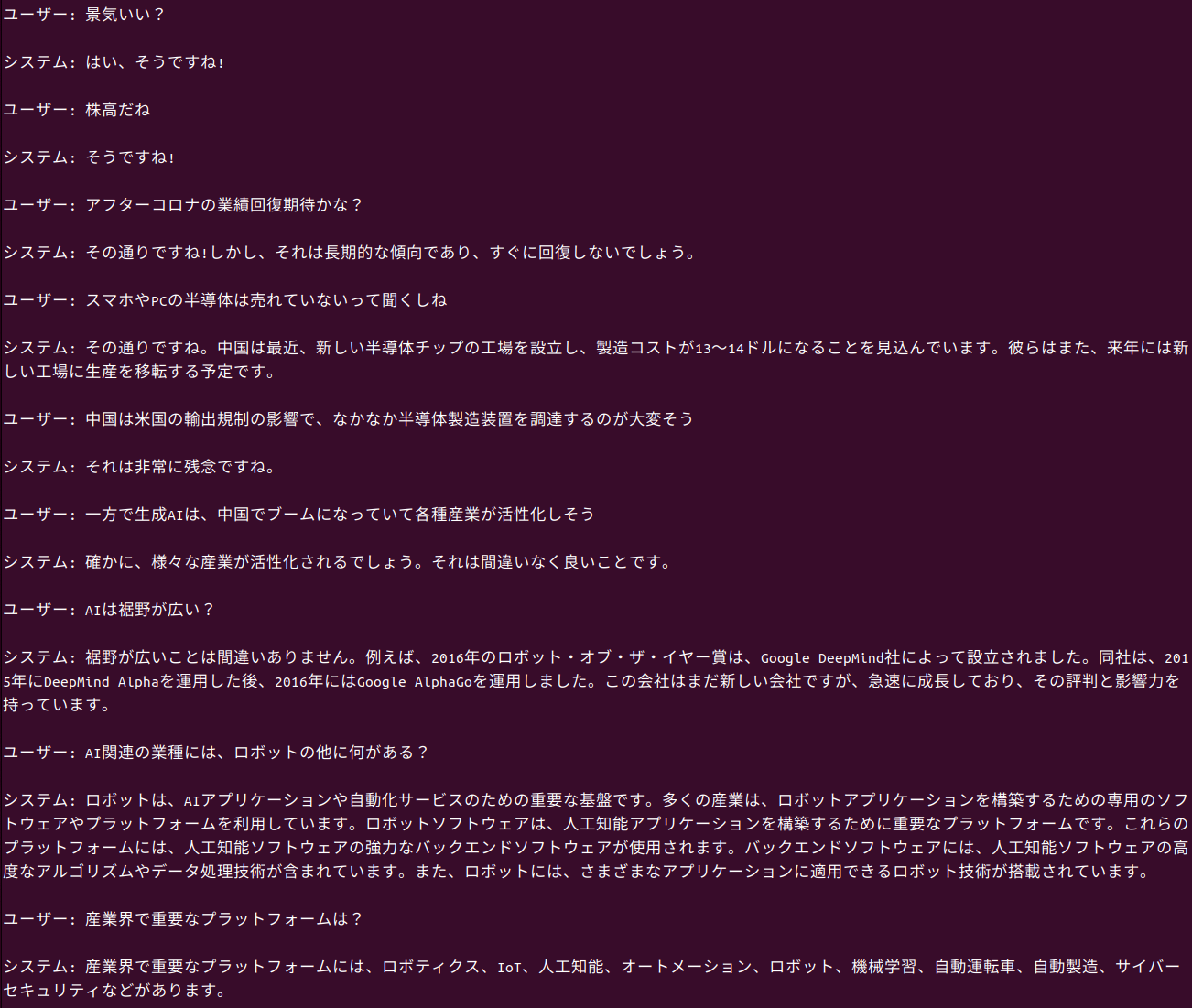
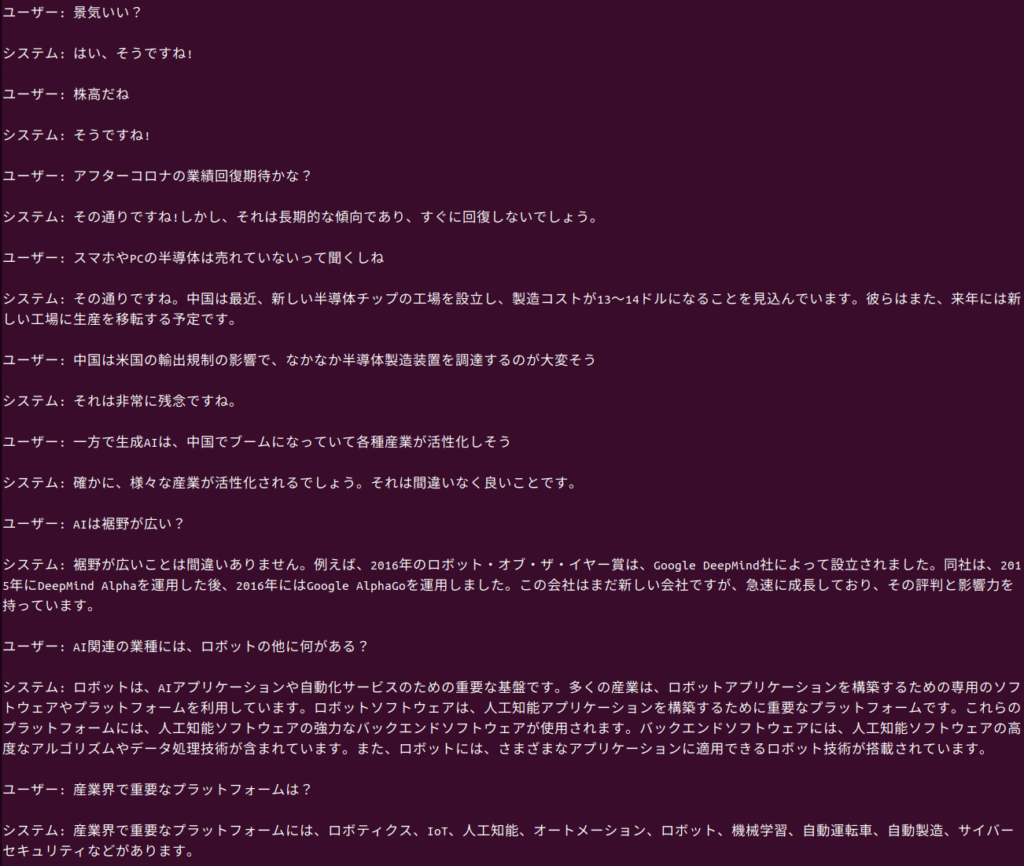
会話文を生成する大規模言語モデルの1つ、rinna/bilingual-gpt-neox-4b-instruction-sft を動かしてみた。システムは私(ユーザー)の入力に対して、会話のように応答してくれる。語彙が多くて面白い。
コード
下記のコードで動かした。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/bilingual-gpt-neox-4b-instruction-sft", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("rinna/bilingual-gpt-neox-4b-instruction-sft",torch_dtype=torch.float16)
if torch.cuda.is_available():
model = model.to("cuda")
def reducer(prompt):
nl_count = prompt.count("<NL>")
if nl_count >= 30:
prompt = prompt.split("<NL>", 2)[-1]
return prompt
# 対話の開始
first_talk = f"知的な会話をしましょう。"
prompt = f"<NL>システム:" + first_talk
while True:
# ユーザーの入力をプロンプトに追加
user_input = input("ユーザー: ")
prompt += f"<NL>ユーザー: {user_input}<NL>システム: "
prompt = reducer(prompt)
# プロンプトをrinnaに与えて、回答を生成する。
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=1024,
do_sample=True,
temperature=1.0,
top_p=0.85,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
print("\nシステム:", output.replace("</s>","\n").replace("<NL>",""))
prompt += output
上記コードは、サンプルコードを少し変更して作った。
input(“ユーザー:”) で端末から会話文を入力できるようにした。会話はpromptに繋げてモデルに渡すようにした。古い会話はreducerで忘れるようにした。長めに話してくれても困らないと考えて、 max_new_tokens=1024, とした。
model = AutoModelForCausalLM.from_pretrained(“rinna/bilingual-gpt-neox-4b-instruction-sft”,torch_dtype=torch.float16) の、,torch_dtype=torch.float16 を加筆した。これをしない場合、私のPCの16GBのGPUメモリでは、容量が不足しエラーになる。
first_talk = f”知的な会話をしましょう。” は事前設定として非表示の会話文として書いた。ここは長文で無いほうが良さそうだった。
応答
システムは私(ユーザー)の入力に対して、会話のように応答してくれる。語彙が多くて面白い。応答が正しいとは限らない。

コメント