BERTと呼ばれる自然言語処理モデルでは、日本語の文章穴埋め機能が提供されている。この機能を使い、関連する単語をリストアップできる。
単語のリストアップ
例えば、資産運用をしていて半導体銘柄に興味があり、半導体に関連する単語を知りたい局面を考える。
この時、
text = '半導体を[MASK]する'として、[MASK]に何が入るか?とBERTに聞くと、下記の答えが返ってきた。BERTへの問い合わせのためのコードと参考書籍は後述する。
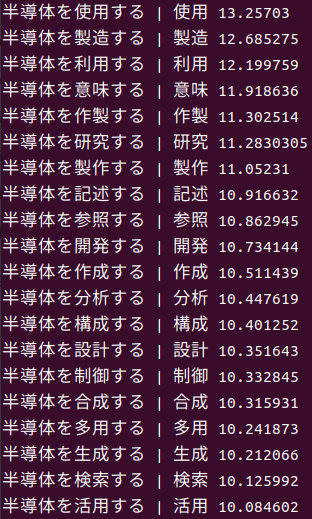
なかなか良い。私が調べたいのは半導体設計銘柄か、半導体製造銘柄か、半導体構成(部品や材料)銘柄か、半導体を使用する銘柄か、BERTはさまざまな切り口を提供してくれる。
検索機能を持つ文章生成AIであるBing AI ChatやBardに詳細を問い合わせる際の、プロンプトの具体性を高めるためのプラスアルファの視点が、上記の回答によって手に入るわけだ。検索は昔からコンピューターの得意分野であり、その強みを活かした使い方が出来ると言える。
今回動詞を導出したが、助詞や語順等を変更して、異なる単語を出力させることもできる。
ただし、難しい単語を入力すると、認識してもらえないことがある。
セットアップとコード
セットアップとコード作成は下記の書籍を参考にした。書籍にはもっと複雑な穴埋めや、文章分類、固有表現抽出、文章校正の方法等が記載されている。
コードは下記。書籍のコードを目的に合わせて変更している。
import numpy as np
import torch
from transformers import BertJapaneseTokenizer, BertForMaskedLM
model_name = 'cl-tohoku/bert-base-japanese-whole-word-masking'
tokenizer = BertJapaneseTokenizer.from_pretrained(model_name)
bert_mlm = BertForMaskedLM.from_pretrained(model_name)
bert_mlm = bert_mlm.cuda()
def predict_mask_topk(text, tokenizer, bert_mlm, num_topk):
tokens = tokenizer.tokenize(text)
print("tokens=",tokens) # 単語の切り口を目視する
input_ids = tokenizer.encode(text, return_tensors='pt')
input_ids = input_ids.cuda()
with torch.no_grad():
output = bert_mlm(input_ids=input_ids)
scores = output.logits
mask_position = input_ids[0].tolist().index(4) # [MASK]のIDは4
topk = scores[0, mask_position].topk(num_topk)
ids_topk = topk.indices
tokens_topk = tokenizer.convert_ids_to_tokens(ids_topk)
scores_topk = topk.values.cpu().numpy()
for i, token in enumerate(tokens_topk):
token = token.replace('##', '')
print(text.replace('[MASK]', token, 1),"|",token,scores_topk[i])
return
text = '半導体を[MASK]する' #名詞が連想する動詞を調べる
predict_mask_topk(text, tokenizer, bert_mlm, 20)
ちなみに上記のBERTのコードは、私の2GのGPUでも動いた。

コメント