Ubuntuのローカル環境で、画像生成AIのstable-diffusion-webuiを試してみた。ソースをダウンロードし解凍、launch.pyを実行しブラウザでアクセスする流れだった。
ダウンロード
ファイルは下記。コードボタンからZIPをダウンロードし、適当なローカルフォルダで解凍する。
GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub...
github.com
起動
解凍したファイルのlaunch.pyを実行する。
cd stable-diffusion-webui-master
python3 launch.py下記のような表示が出れば良いらしい。
Model loaded in 40.8s (load weights from disk: 1.4s, create model: 0.4s, apply weights to model: 37.8s, apply half(): 0.5s, move model to device: 0.5s, calculate empty prompt: 0.1s).ブラウザで下記にアクセスすれば、Stable-diffusion-webuiを利用できる。
http://localhost:7860/画像を作る
欲しい画像に関するキーワード、除外するキーワード(下の場合、絵)を打ち込み、生成するをクリックすると画像ができる。
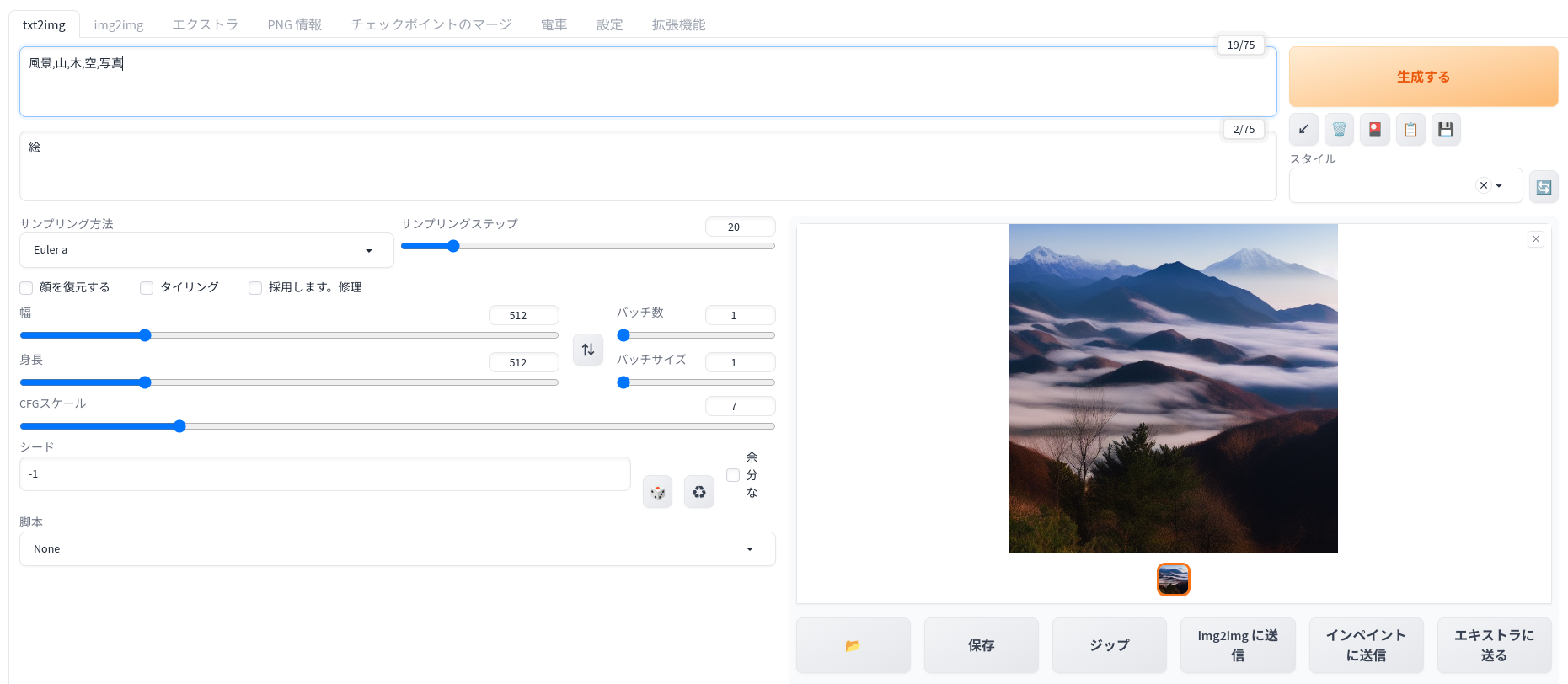
画像のキーワードを「風景,山,木,空,写真」、除外キーワードを「絵」にして何度か試してみた。良い画像が出ることもあるようだ。

今後、設定に詳しくなって思い通りの画像を出したい。


コメント